



AI data center networking is now a direct driver of AI performance. In a traditional data center, the network mainly supports application traffic, storage access, and routine east-west communication. In an AI cluster, the network affects how quickly GPUs can exchange data, synchronize work, and finish each training step.
That shift matters because AI workloads generate tightly coordinated traffic across many servers at once. Instead of many unrelated flows moving independently, AI jobs often create synchronized bursts that hit links, buffers, and switches together. A small delay on one path can slow a much larger part of the job.
Key Takeaways:
- Collective communication creates the biggest AI network bottlenecks by driving synchronized congestion across many GPUs at once.
- Tail latency and uneven load balancing reduce GPU utilization because distributed training waits for the slowest flows.
- RoCE fabrics need careful congestion, queue, and loss control to avoid retransmissions and unstable training performance.
- Topology, observability, and fast failure recovery strongly influence AI cluster efficiency, scalability, and operational stability.
What Makes AI Data Center Networking Different
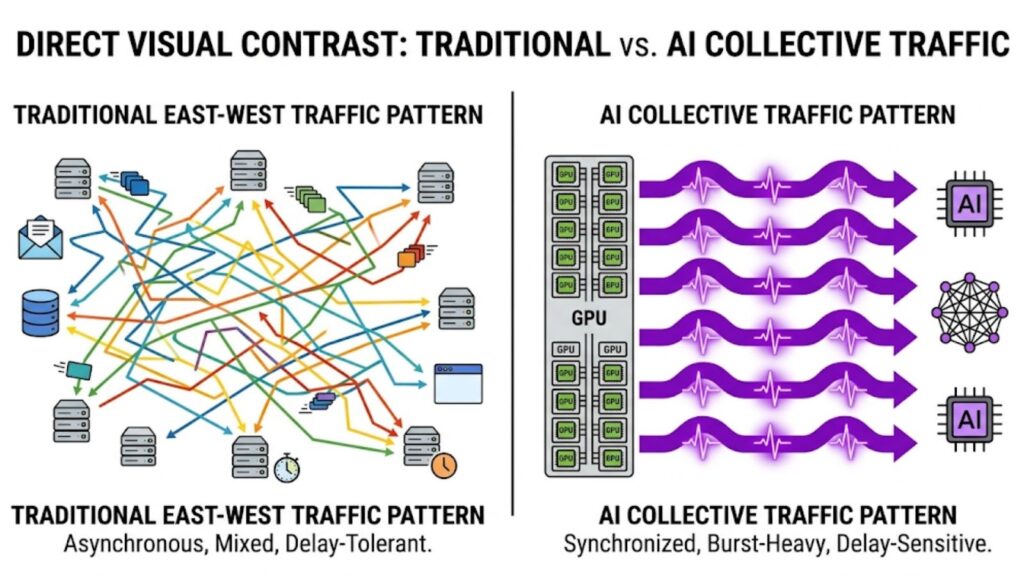
AI training and inference traffic vs traditional east-west traffic
Traditional east-west traffic is mixed, less synchronized, and often tolerant of delay. AI traffic is different. It is more predictable, more repetitive, and far more sensitive to network behavior.
Key differences include:
- Higher bandwidth demand: large data exchanges between GPUs
- Synchronized communication: many nodes transmit at the same time
- Burst-heavy patterns: traffic arrives in short, intense spikes
- Low tolerance for delay: small latency increases affect the whole job
This is why AI environments expose network limitations much faster than standard enterprise workloads, especially when planning decisions like GPU deployment strategy directly shape network performance.
Why synchronized collective communication changes network design
AI training relies on collective operations such as AllReduce, AllGather, ReduceScatter, and All-to-All. These patterns coordinate communication across many nodes in fixed stages.
That changes network priorities in several ways:
- Traffic is coordinated, not random
- Multiple nodes send and receive simultaneously
- Performance depends on the slowest path
- Burst handling becomes more important than averages
As a result, operators must design networks for consistency and predictability, not just peak throughput, which is why many teams align these decisions with broader hybrid infrastructure design considerations.
The Biggest Challenges in AI Data Center Networking
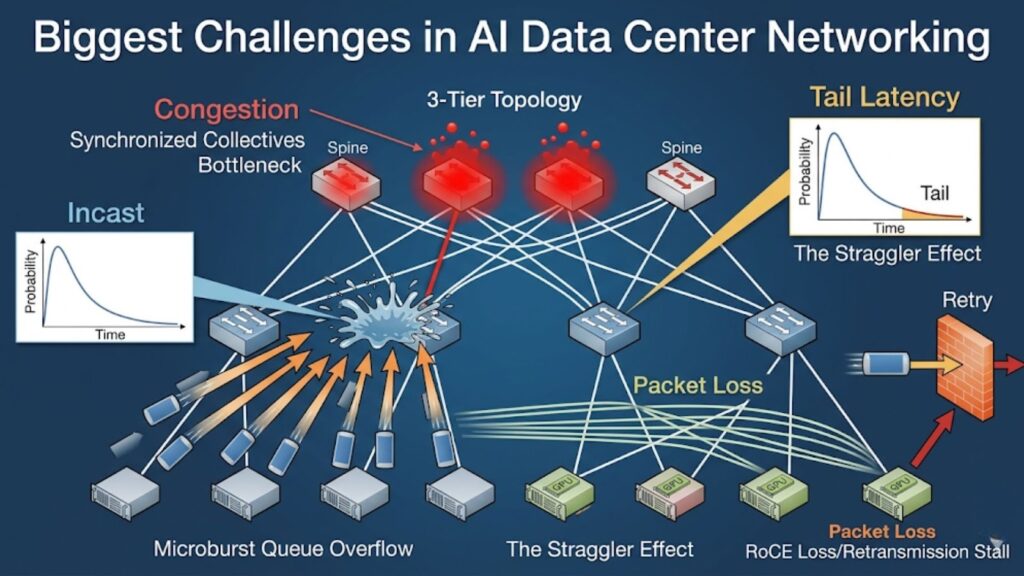
Congestion from AllReduce, AllGather, ReduceScatter, and All-to-All
Collective operations are one of the main reasons AI networks become congested. These patterns move large volumes of data across many GPUs in repeated, tightly timed cycles. If the fabric cannot absorb that demand cleanly, step time rises and GPUs wait.
These operations create pressure because they:
- Involve many nodes at the same time
- Repeat across every training step
- Generate synchronized bursts instead of smooth traffic
- Increase sensitivity to delay on any single path
Each collective adds stress in a different way:
- AllReduce: synchronizes updates across workers
- AllGather: shares data from each worker to all workers
- ReduceScatter: combines data, then splits results across workers
- All-to-All: creates dense many-to-many exchange patterns
This is where switching architecture becomes a major design factor. In large Ethernet AI fabrics, Arista is often part of the discussion because operators need strong path efficiency, low-latency switching, and deep visibility across synchronized GPU traffic.
Incast, microbursts, and burst-heavy traffic patterns
AI traffic is not only heavy. It is also highly bursty. Many senders may target the same receiver at once, creating incast. At the same time, very short spikes can create microbursts that fill queues before average monitoring metrics show a problem.
These patterns are hard to manage because they can:
- Overwhelm buffers in a short time
- Create sudden delay even on healthy links
- Trigger packet drops or unstable throughput
- Stay hidden behind normal-looking average utilization
That is why average bandwidth charts can be misleading in AI environments. A network may look underused overall while still suffering short bursts that disrupt training performance.
This is also why physical design choices, including cooling and density planning, can affect network stability in dense AI deployments.
Table: Key AI networking terms
| Term | Simple definition | Why it matters in AI clusters |
| AllReduce | Aggregates data across all workers | Central to distributed gradient sync |
| AllGather | Collects data from all workers to all workers | Common in sharded and parallel training |
| ReduceScatter | Reduces data, then distributes pieces | Helps split communication efficiently |
| All-to-All | Every participant exchanges data with every other | Important in communication-heavy models |
| Incast | Many senders target one receiver | Can overwhelm buffers quickly |
| Microburst | Very short traffic spike | Creates hidden queue stress |
Uneven load balancing across equal-cost paths
AI fabrics often use equal-cost multipath routing to spread traffic across links. But AI flows can look very similar, so traffic does not always distribute evenly.
That creates hot links, underused paths, and inconsistent job performance. This is why fine-grained load balancing and traffic steering matter in AI clusters.
In large Ethernet AI back-end fabrics, platforms from vendors such as Arista are often evaluated for their ability to maintain path efficiency and provide deeper visibility into traffic distribution across the network.
Tail latency and straggler effects in distributed training
Tail latency matters more than average latency in AI clusters. Distributed training often waits for the slowest flow to finish each step.
That means a small delay can hold back many GPUs at once. In large environments, these straggler effects can stretch training time and reduce utilization.
This is why infrastructure buyers increasingly look at the full stack, not only the network in isolation, with solutions from vendors such as Dell Technologies often evaluated for how well they align GPU servers, storage performance, and network behavior across the entire AI environment.
Packet loss and retransmission overhead in RDMA/RoCE environments
Many AI environments use RDMA over Converged Ethernet, or RoCE, to support low-latency communication with less CPU overhead. It can perform well, but it is highly sensitive to congestion and queue behavior.
Packet loss is especially harmful because it can:
- Trigger retransmissions
- Stall communication
- Reduce throughput consistency
- Waste expensive GPU time
That is why operators pay close attention to:
- Congestion signaling
- Queue thresholds
- Flow control settings
- End-to-end transport tuning
HPE often enters this discussion when teams evaluate AI and HPC infrastructure together, because transport-aware design and Ethernet tuning have a direct effect on cluster stability. This is also why some organizations connect RoCE planning to broader AI-ready network design decisions early in the project.
Link, NIC, and switch failures that stall large training jobs
As AI clusters grow, failures become harder to absorb. A bad optic, unstable NIC, link flap, or switch problem can affect far more than one server. If recovery is slow or fault isolation is weak, a large training job may degrade or stall.
The challenge is not only reducing failure rates. It is building a design that limits blast radius and restores stable communication quickly. In large-scale AI environments, that recovery model should be evaluated as carefully as throughput.
Scaling from leaf-spine to rail-optimized and multi-plane fabrics
Many teams start with leaf-spine architectures because they are familiar and scalable. As clusters grow, some move toward rail-optimized or multi-plane designs to improve traffic locality, path diversity, and fault isolation.
There is no single best topology for every AI deployment. The right choice depends on workload behavior, cluster size, growth goals, and how the organization plans to scale over time. Teams also need to weigh performance goals against operational simplicity and long-term network cost control considerations.
Observability gaps in dense AI network environments
Traditional monitoring is often too shallow for AI fabrics. Interface counters and average latency views do not show where collective communication slows down, where path imbalance forms, or where queues are building pressure.
Dense AI environments need stronger observability. Teams need better flow visibility, congestion telemetry, and the ability to connect network symptoms with training slowdowns. Juniper Networks is often mentioned when the discussion shifts toward operations, assurance, and network-wide visibility, especially for organizations that place heavy value on operational analytics alongside raw network throughput.
Why These Challenges Hurt AI Performance
Network problems in AI clusters do more than reduce link efficiency. They waste GPU cycles, extend training time, and increase the cost of each model run.
The biggest effects usually show up in four ways:
- Lower GPU utilization
- Longer training completion times
- Higher infrastructure cost per run
- Greater operational risk at cluster scale
Table: Top AI networking challenges and impact
| Challenge | Why it happens | Business or technical impact | Priority level |
| Congestion from collectives | Many nodes exchange data in synchronized steps | Slower training and lower throughput | High |
| Incast and microbursts | Burst-heavy many-to-one traffic patterns | Queue pressure and unstable performance | High |
| Uneven load balancing | Similar flows distribute poorly across equal-cost paths | Hot links and inconsistent job times | High |
| Tail latency | Slowest flow delays the whole step | Lower GPU utilization | High |
| Packet loss in RoCE fabrics | Congestion and poor tuning disrupt transport behavior | Retransmissions and stalls | High |
| Failure recovery at scale | More components increase fault exposure | Job disruption and operational risk | Medium-High |
| Observability gaps | Traditional tools miss AI-specific symptoms | Slower troubleshooting | High |
How Operators Address These Challenges
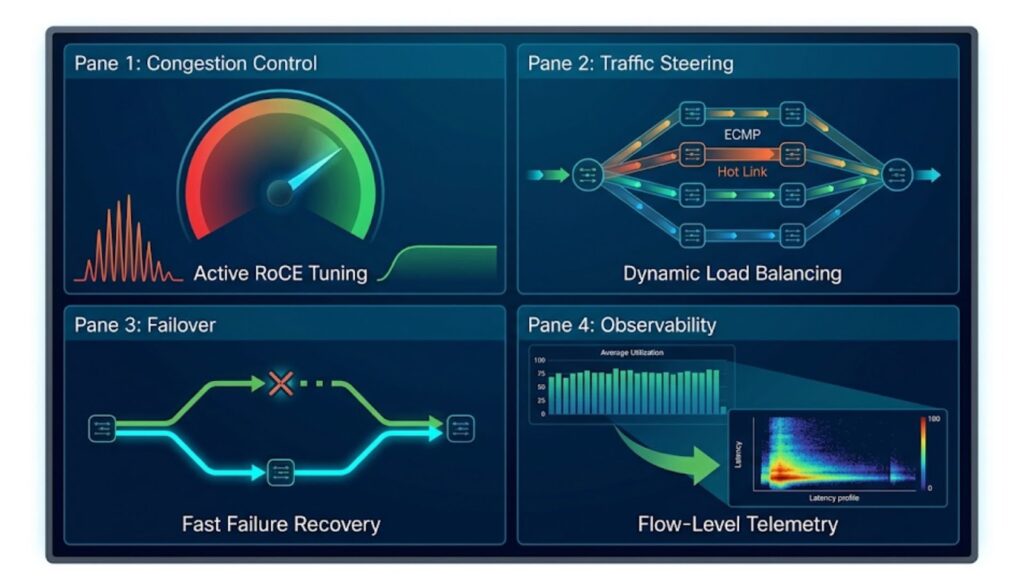
Better congestion control and queue management
Operators start by reducing the effects of synchronized traffic bursts. In AI clusters, congestion is not occasional. It is built into the traffic pattern, especially during collective communication.
To control that pressure, teams focus on:
- Queue tuning for burst-heavy traffic
- Congestion signaling that reacts early
- Buffer management that reduces sudden overflow
- Transport settings that keep flows stable under load
The goal is not just higher throughput. It is more predictable communication from step to step.
Fine-grained load balancing and traffic steering
AI traffic does not always spread evenly across equal-cost paths. That is why operators use more precise traffic steering instead of relying only on standard hashing behavior.
Key priorities usually include:
- Better path distribution across parallel links
- Faster detection of hot spots
- Traffic steering that adapts to real flow behavior
- Reduced imbalance during collective-heavy workloads
This helps improve consistency, not just peak bandwidth. In AI training, steady performance often matters more than isolated speed.
Fast failure detection and failover design
Large AI clusters need to recover quickly when a link, NIC, or switch fails. A small fault can create a much larger performance problem if the network cannot isolate it fast enough.
Operators typically design for:
- Fast fault detection
- Limited blast radius
- Clear failover behavior
- Faster recovery during live jobs
The real value is keeping the cluster productive even when infrastructure issues appear.
Topology planning for scale-up and scale-out environments
Topology decisions affect how well the cluster performs as it grows. A design that works for a smaller deployment may not hold up when GPU count and communication intensity rise together.
Operators usually plan for:
- Local GPU communication inside smaller domains
- Efficient cross-rack traffic movement
- Clear scaling paths for future expansion
- Better fault isolation as the fabric grows
This is also where broader infrastructure choices matter, including GPU deployment strategy and long-termnetwork cost control.
Telemetry, observability, and proactive troubleshooting
Traditional monitoring is often too limited for AI environments. Operators need visibility that shows where congestion builds, where traffic becomes uneven, and how network behavior affects training jobs.
Useful observability usually includes:
- Flow-level visibility
- Queue and congestion telemetry
- Path-level troubleshooting
- Correlation between network events and training slowdowns
The strongest operations teams use this data before failures become major disruptions. That makes observability part of performance management, not just troubleshooting.
How to Evaluate an AI Data Center Network

A strong AI network design should be evaluated on more than speed and port count. Buyers should look at how the environment behaves under synchronized load, how faults are handled, and how clearly the operations team can see performance problems.
Good evaluation questions include:
- How does the design handle collective-heavy traffic?
- What does tail latency look like under AI load?
- How are congestion and packet loss managed?
- What topology limits appear as the cluster grows?
- How quickly can the environment detect and isolate failures?
- How well do the components work across compute, storage, and network layers?
How Catalyst Data Solutions Inc. Helps Evaluate and Deploy AI Networking Infrastructure
Choosing an AI network is not just about switch speed or port count. It requires alignment across topology, transport behavior, observability, recovery design, compute density, and long-term operational fit.
Catalyst Data Solutions Inc. helps organizations evaluate and deploy AI networking infrastructure by connecting architecture choices to real deployment needs across GPU clusters, storage, power, cooling, and implementation planning.
FAQ
Why is AI data center networking harder than traditional networking?
Because AI workloads create synchronized, burst-heavy traffic that makes congestion, latency, and imbalance more visible.
What is the biggest bottleneck in AI training networks?
In many clusters, the biggest bottleneck is congestion during collective communication.
Why does tail latency matter so much in AI clusters?
Because distributed training often waits for the slowest flow or node to complete a synchronized step.
Is Ethernet good enough for large AI clusters?
Yes, if the topology, transport tuning, observability, and congestion handling are designed for AI traffic behavior.
What is the role of RoCE in AI networking?
RoCE supports RDMA over Ethernet, helping improve communication efficiency in distributed AI workloads.
Which topology is best for AI data center networking?
There is no single best choice. The right topology depends on workload behavior, scale, and long-term growth plans.
How do network failures affect distributed AI training?
Failures can slow, degrade, or stall training jobs, especially when recovery is slow or fault isolation is weak.